EMG results
Results and analysis
Thirty seven sets of EMG traces are attached representing one subject's performance with the 37 test tokens. In each case the speech waveform accompanies the 3 EMG traces and all 4 channels are time-aligned. The horizontal axis represents time for all four channels whilst the vertical axis represents amplitude.
Please Note: To see these EMG traces, click on the link in any of the cells in the following table that contains phonetic script. ...OR... if you wish to scroll through the EMG traces in order, click on the first one then use the left and right arrows when hovering to the left or right of of the images.
All of these EMG images are also available in a print formatted PDF file.
| i: | e: | o: | ʉ: | ɐ: | ɔ: | |
| i:hi: | ʉ:hʉ: | e:he: | æ:hæ: | ɐ:hɐ: | ||
| i:hʉ: | ʉ:hi: | y:hʉ: | ʉ:hy: | |||
| i:bi: | i:pi: | ʉ:bʉ: | ʉ:pʉ: | e:be: | e:pe: | |
| æ:bæ: | æ:pæ: | ɐ:bɐ: | ɐ:pɐ: | |||
| i:bʉ: | ʉ:bi: | y:bʉ: | ʉ:by: | |||
| i:f | i:v | ɐ:f | ɐ:v | |||
| i:p | i:b | ɐ:p | ɐ:b |
The actual amplitudes of the EMG traces for each of the three electrodes is arbitrary, being dependent on adequacy of electrode placement, the setting of the biological amplifier and the gain of each channel on the graphical display. For this reason it is not possible to compare absolute levels of muscle activity between the three electrodes. On the other hand, the various gains for each electrode, once set, remain constant for the entire experiment (for a single subject only). This means that the activity for any one electrode can be accurately compared from one token to another.
What can be compared between the electrodes is the relative position of peaks (activation) and dips (inhibition) and where these peaks and dips occur relative to vowel or consonant onsets, stop bursts, etc.
In the case of the orbicularis oris trace, for example, there is some activity for most tokens. What you need to observe is the relative level of that activity from one token to the next. For example, orbicularis oris activity is approximately level for /ʉ: ɐ: i:/ but the intensity is medium to low for /i:/, high for /ʉ:/ and almost entirely absent for /ɐ:/.
For some tokens there is a noticeable activity peak or dip. Where do such features occur relative to the features of the speech waveform? What are the other muscles doing at that time?
It is extremely helpful to read the Öhman articles (especially Öhman, 1967) first so that you are able to predict the activity of the muscles for each class of sounds. Öhman's studies had the advantage of being able to utilise needle electrodes and so muscles could be selected with some accuracy. In the present experiment the surface electrodes often pick up the activity of more than one muscle.
Electrode 3 definitely picks up the activity of the two levator muscles (as suggested in the experiment methodology section) and so the pattern displayed is often a complex combination of two patterns. What, for example, would you expect to happen if inhibition is predicted for the levator labii superioris and activation is predicted for the levator anguli oris? A peak of activity would be expected at the same place as a dip in the activity. If they are of the same relative intensity they will cancel each other out, otherwise the stronger effect will predominate. Try to determine which muscle's activity is being demonstrated whenever a peak or a dip occurs in the electrode 3 trace.
Electrode 2 can usually be explained (for the present set of data) by reference to Ohman's predictions for the depressor labii inferioris but it is possible that some activity from the depressor anguli oris may also be contaminating the results.
Don't try to read too much into the numerous tiny peaks and dips in the EMG fine detail. Look for the major trends and the major peaks and dips. Also, attend more closely to changes which occur at the junction between two sounds.
Some notes on tabulating your observations
It is very helpful to attempt to tabulate your observations (and even better if you can invent some means of presenting the data graphically). To do this you will need to divide up the timescale into phonetically sensible divisions. That is, you will need to segment each token. At the simplest level, this means that you would divide up the waveform into its component vowels and consonants and notate the activity of the three electrodes for each of these phonetic segments. In practice, however, it is far more desirable to further sub-segment the waveform. Firstly, note the activity at the onset of each segment. The onset is defined (for the purposes of this experiment) as the first part (say about 1/8 of the total length) of the present segment. Also include in the definition of the onset the last part of the preceding segment (or preceding silence for an initial segment). This is because any change towards the end of a phonetic segment is likely to reflect anticipation of the following segment (for this reason it is unnecessary, for our purposes, to make a separate notation of activity during a segment's offset). As well as the onset of a segment, it is (of course) still necessary to note the activity during a segment's nucleus. Sometimes anticipatory muscle movements may occur during the preceding segment's nucleus (when they do not conflict with the postural requirements of that segment) and if such anticipatory movement occurs during a segment nucleus then it must be coded in the table as occurring during that nucleus and not during the following onset. Stops are a bit more complex, as occlusions and bursts need to be treated separately. In this case (for example) a peak of activity commencing near the end of an occlusion and overlapping the burst will be considered to be burst activity.
Invent a notation that will enable you to readily tabulate the presence of peaks and dips, and level activity of different relative intensities.
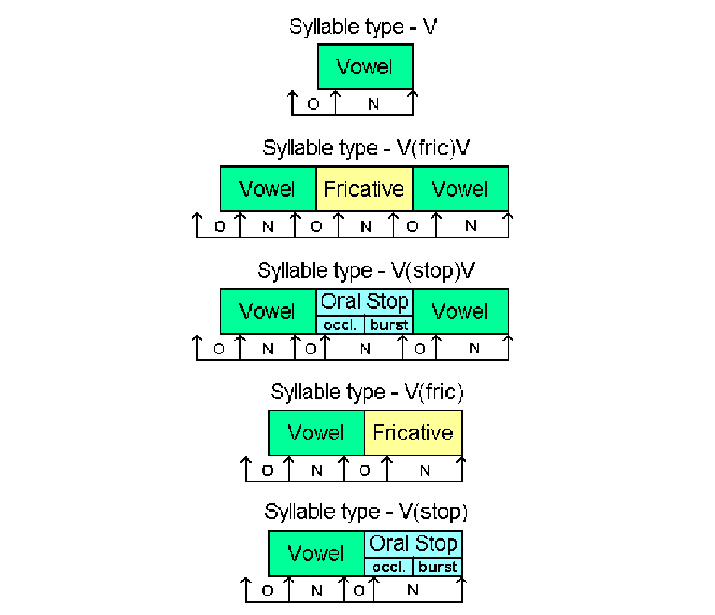
Figure 1: Approximate locations of onsets (O) and nuclei (N) for the various token types found in this experiment. The boundaries are only approximate. The onsets include the offset of the preceding segment (or the preceding silence for an initial vowel). This is not normal practice, but is useful for the present experiment as any changes in the last 1/8 of a segment will be due to the muscles preparing themselves for the lip posture required for the following sound.
Content owner: Department of Linguistics Last updated: 12 Mar 2024 9:23am